R로 크롤링하기 - 보배드림 예제
페이지 정보

본문
크롤링은 기본적인 과정은 web의 html 파일을 가져온 후, 파싱(parsing)을 해서 원하는 데이터에 접근하게 됩니다. parsing 방법에는 html 태그 혹은 css나 id 를 통해 원하는 데이터에 접근하는 방식과 html의 트리 구조를 이용하여 접근하는 XML 방식이 있습니다. 본 포스팅에서는 태그와 css를 이용해 접근하는 방식을 사용해 보겠습니다.
먼저, rvest 패키지를 설치합니다.
install.packages('rvest')보배 드림 사이트 바로 긁어와 보기
본 실습에서는 중고차 사이트인 보배드림을 예로 들겠습니다.
아래는 해당 사이트의 html 태그를 가져와서 parsing하는 작업입니다.
#내가 수집하길 원하는 페이지 주소
url <- "http://www.bobaedream.co.kr/cyber/CyberCar.php?gubun=K&page=1"
usedCar <- read_html(url) #해당 url 페이지의 html tag를 가져와서 parsing함.
usedCar## {xml_document}
## <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
## [1] <head>\n <title>중고차, 중고자동차, 중고차매매 | 보배드림 국산차매장</title>\n <meta htt ...
## [2] <body> \n<!--wrap--> \n<div class="wrap"> \n \n<link ...이제부터 사이트 구조를 잘 파악해야 하는데, 예를 들어 제가 관심있는 정보가 자동차 종(type), 변속기(transmission), 연료종류(fuel), 거리(distance) 라고 합시다. 이 정보는 모두 .carinfo 라는 class 안에 들어가 있는 걸 확인할 수 있습니다. 이건 어떻게 확인하냐구요? 그건 chrome 이나 explorer 에서 F12키를 누르면 아래와 같이 개발자 도구창이 뜹니다.
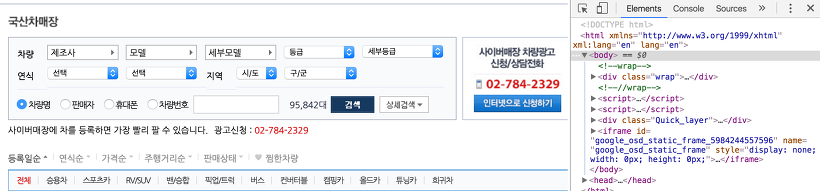
이를 통해, 현재 웹 페이지의 html을 볼 수 있는데요.
좌측 상단에 네모위에 화살표가 그려져 있는 아이콘이 있는데 그걸 클릭후
아래와 같이 웹 페이지에서 원하는 부분을 선택해보세요.
그럼 웹 페이지에 대응하는 html 태그를 개발자 모드 창에서 확인할 수 있습니다.
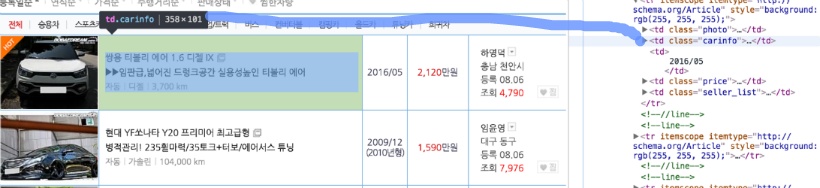
위 그림과 같이 우리가 원하는 정보는 <td class = "carinfo"> ... </td> 안에 묶여 있는 걸 알 수 있습니다. 따라서 먼저 carinfo 안의 모든 정보를 가져와 보겠습니다.
#parsing한 usedCar 에서 css가 'carinfo' 인 것을 찾아라.
carInfos <- html_nodes(usedCar, css='.carinfo')
head(carInfos)## {xml_nodeset (6)}
## [1] <td class="carinfo"><a href="/cyber/CyberCar_view.php?no=640718& ...
## [2] <td class="carinfo"><a href="/cyber/CyberCar_view.php?no=641415& ...
## [3] <td class="carinfo"><a href="/cyber/CyberCar_view.php?no=641410& ...
## [4] <td class="carinfo"><a href="/cyber/CyberCar_view.php?no=641379& ...
## [5] <td class="carinfo"><a href="/cyber/CyberCar_view.php?no=641386& ...
## [6] <td class="carinfo"><a href="/cyber/CyberCar_view.php?no=641421& ...따라서 50개의 ‘.carinfo’ tag가 있기 때문에, carInfos에는 50개의 값이 벡터 형태로 담깁니다. 먼저 첫번째 경우만 예를 들어볼게요.
#가장 첫번째 cafInfos로부터 정보 추출해보면,
carInfos[1] %>% html_nodes('.title') %>% html_text()## [1] "쌍용 티볼리 에어 1.6 디젤 IX"이처럼 제목이 잘 출력된 것을 알 수 있습니다. 그런데 50개 모든 제목을 추출하고 싶으면 carInfos[1] 에서 index만([1]) 제거해 주면 됩니다. 자동으로 50개의 원소에 함수를 적용해 주는 것이죠(마치 apply 처럼)
titles <- carInfos %>% html_nodes('.title') %>% html_text()
head(titles)## [1] "쌍용 티볼리 에어 1.6 디젤 IX"
## [2] "현대 YF쏘나타 Y20 프리미어 최고급형"
## [3] "르노삼성 QM3 RE"
## [4] "현대 그랜져TG 아제라"
## [5] "기아 포르테 쿱 2.0 CVVT 프레스티지"
## [6] "기아 K7 VG270 럭셔리 프리미엄"변속기, 연료 정보 등은 sub_01이라는 class 안에 있군요. 따라서
carDetainInfo <- carInfos %>% html_nodes('.sub_01') %>% html_text()
head(carDetainInfo)## [1] "자동ㅣ디젤ㅣ3,700 km" "자동ㅣ가솔린ㅣ104,000 km"
## [3] "자동ㅣ디젤ㅣ32,000 km" "자동ㅣ가솔린ㅣ54,440 mi"
## [5] "수동ㅣ가솔린ㅣ32,000 km" "자동ㅣ가솔린ㅣ120,000 km"흠… 그런데! “자동ㅣ가솔린ㅣ41,000 km” 과 같이 하나의 문자에 정보가 묶여 있네요. 이를 특정 기호를 기준으로 분리해야 우리가 최종적으로 원하는 결과를 얻을 수 있을 것 같습니다.
stringr
이때, 사용하는게 Hadley아저씨("http://hadley.nz/")가 만든 string다루는 library, stringr 입니다.
stringr을 사용하면 문자열을 특정 기호를 기준으로 분할 하거나, 특정 패턴(정규표현식)의 문자를 다른 문자로 바꿔주는 등 string을 다양하게 다룰 수 있습니다.
install.packages('stringr')library(stringr)
carInfos[1] %>% html_nodes('.sub_01') %>% html_text()## [1] "자동ㅣ디젤ㅣ3,700 km"1) ‘ㅣ’ 이라는 문자를 기준으로 나누고 싶을때는? : str_split(문자, ‘분리하고 싶은 문자’)
(주의할 것은 키보드에 있는 | 표시와는 다른 문자에요! 복붙 해주세요.)
str_split(carInfos[1] %>% html_nodes('.sub_01') %>% html_text(), 'ㅣ')## [[1]]
## [1] "자동" "디젤" "3,700 km"2) 쉼표, 문자를 제거하고 싶다면? : str_replace(문자, ‘제거하고 싶은 패턴’,‘대체하고 싶은 패턴’)
아래 예제를 몇 개 볼게요.
str_replace('20,000km', '0', '')## [1] "2,000km"str_replace_all('20,000km', '0', '')## [1] "2,km"str_replace_all('20,000Km', '[a-zA-Z]', '') #영어 소문자, 대문자 모두## [1] "20,000"str_replace_all('100,운용리스','[,가-하]','') #한글도 마찬가지로 가~하까지 모두## [1] "100"str_replace_all('20,000Km', '[,Km]', '')## [1] "20000"자 이제, 다시 정리해 볼게요.
#먼저 첫페이지의 모든 제목 정보를 가져오는 명령어는
titles <- carInfos %>% html_nodes('.title') %>% html_text()변속기, 연료, 거리는 “자동ㅣ가솔린ㅣ41,000 km”과 같이 특정 문자로 분할하기 위해 lapply를 적용합니다.
splitFunction <- function(row){
return(str_split(row, 'ㅣ')[[1]])
}
carDetailInfo <- lapply(carInfos %>% html_nodes('.sub_01') %>% html_text(), splitFunction)
head(carDetailInfo)## [[1]]
## [1] "자동" "디젤" "3,700 km"
##
## [[2]]
## [1] "자동" "가솔린" "104,000 km"
##
## [[3]]
## [1] "자동" "디젤" "32,000 km"
##
## [[4]]
## [1] "자동" "가솔린" "54,440 mi"
##
## [[5]]
## [1] "수동" "가솔린" "32,000 km"
##
## [[6]]
## [1] "자동" "가솔린" "120,000 km"여기에 마무리 작업으로 뭘 하면 될까요? 각각의 데이터를 하나의 자료구조 즉, data.frame 형태로 바꿔야 겠죠. 먼저, 가져온 carDetailInfo는 list이기 때문에 이를 matrix로 바꾸면
carDetailInfo <- matrix(unlist(carDetailInfo), ncol=3, byrow=T)
head(carDetailInfo)## [,1] [,2] [,3]
## [1,] "자동" "디젤" "3,700 km"
## [2,] "자동" "가솔린" "104,000 km"
## [3,] "자동" "디젤" "32,000 km"
## [4,] "자동" "가솔린" "54,440 mi"
## [5,] "수동" "가솔린" "32,000 km"
## [6,] "자동" "가솔린" "120,000 km"#그리고 carDetailInfo 로부터 각각의 정보를 가져오자
transmission <- carDetailInfo[,1]
fuel <- carDetailInfo[,2]
distance <- as.numeric(str_replace_all(carDetailInfo[,3], '[,a-z]','')) #숫자 형태로 바꿔주기 위해따라서 최종적으로 첫페이지에서 수집한 정보는 아래와 같이 data.frame으로 담을 수 있겠죠.
data <- data.frame(titles, transmission, fuel, distance)
head(data)## titles transmission fuel distance
## 1 쌍용 티볼리 에어 1.6 디젤 IX 자동 디젤 3700
## 2 현대 YF쏘나타 Y20 프리미어 최고급형 자동 가솔린 104000
## 3 르노삼성 QM3 RE 자동 디젤 32000
## 4 현대 그랜져TG 아제라 자동 가솔린 54440
## 5 기아 포르테 쿱 2.0 CVVT 프레스티지 수동 가솔린 32000
## 6 기아 K7 VG270 럭셔리 프리미엄 자동 가솔린 120000Quiz
- 위와 비슷하게 가격, 조회수 등도 가져와 보세요
- for 문을 활용하여 10 page 까지 수집해 보세요.
#hint:
#아래 paste0 함수를 사용하여 뒤에 숫자만 바꿔주면서 수집하면 됩니다.
url <- paste0("http://www.bobaedream.co.kr/cyber/CyberCar.php?gubun=K&page=",i)
출처: http://insightteller.tistory.com/entry/R로-크롤링하기-보배드림-예제 [Be a Insight teller]
관련링크
댓글목록
등록된 댓글이 없습니다.